Welcome, fellow tech enthusiasts! If you’re reading this, you’re likely just as intrigued by the world of Large Language Models (LLMs) and prompt engineering as I am. As a newbie, I’ve decided to document my journey to better understand LLMs, their capabilities, and the potential they hold for us in the future.
In this blog post, you’ll find my personal notes, thoughts, and discoveries, all captured in a casual, conversational style. You won’t find any complex definitions or heavy jargon here - just simple explanations and relatable examples that can help both beginners and experienced readers alike.
I’ll be covering a range of topics, from the basic concepts of prompt engineering to the practical application of prompts in working with GPT models. Throughout this post, I’ll share a few techniques I’ve picked up, the definitions I’ve come to understand, and some of the thoughts and questions that have arisen along the way.

As I began my journey into prompt engineering and LLMs, I came across several valuable resources and articles that helped me better understand the concepts and techniques involved:
- Prompt Engineering Guide by DAIR.AI
- Best practices for prompt engineering with OpenAI API
- Building LLM applications for production by Chip Huyen
- AI Devs Course by Adam Gospodarczyk and Jakub Mrugalski
So, without further ado, let’s embark on this exciting adventure together as we explore the world of prompt engineering and LLMs, and uncover their true potential in revolutionizing the tech landscape!
What is Prompt Engineering?
So, you might be wondering, what’s this whole prompt engineering thing about? Well, it’s basically a mix of art and science that helps us get the best out of those super-smart Large Language Models (LLMs) like GPT. It’s all about coming up with questions or statements that nudge the model into giving us exactly what we want in the responses.
The secret sauce of prompt engineering is making those prompts as clear and effective as possible. That way, we can get the LLMs to work like well-oiled machines, giving us super helpful answers without any of the irrelevant stuff we don’t need.
For me, as a developer, prompt engineering is like a magical combo of language skills, tech know-how, and understanding how LLMs think. You can use it to get the LLMs to do all sorts of cool stuff, like writing code, answering questions, or even generating memes! Stick around for more fun tidbits and techniques as we keep exploring this awesome world together!
OpenAI Playground: Our Interactive LLM Sandbox
Before we dive into the nitty-gritty of prompt engineering, let’s take a quick look at the OpenAI Playground. This is a great place to get started with LLMs and prompt engineering, as it lets you play around with the models and see how they work.
It’s worth mentioning that the Playground offers two modes for interacting with LLMs: the “complete” mode and the “chat” mode. Each mode has its own unique flavor and provides a different way of experiencing the power of LLMs.
In the “complete” mode, we can give the model a partial text prompt, and it’ll do its best to fill in the blanks or complete the thought for us. This is great for generating code or writing stories.
 Figure 1: The “complete” mode in the OpenAI Playground
Figure 1: The “complete” mode in the OpenAI Playground
On the other hand, the “chat” mode lets us have a more conversational exchange with the LLM. We can send a series of messages (either from a user or the AI assistant), and the model will generate a response that’s more context-aware and interactive.
 Figure 2: The “chat” mode in the OpenAI Playground
Figure 2: The “chat” mode in the OpenAI Playground
You can also set a system persona for the AI assistant, which will give it a unique personality and style of responding. It’s perfect for simulating a dialogue, asking questions, or getting a more dynamic and engaging output from the LLM.
One of the cool things about the OpenAI Playground is that it gives us the power to choose the LLM model we want to work with and customize its settings to our liking. This flexibility allows us to fine-tune our interactions and get the most out of our prompt engineering experiments.
For instance, we can choose models like “gpt-3.5-turbo” and then tweak the temperature, top-p, frequency penalty, and presence penalty settings to get the best results:
- Temperature: This setting controls the randomness of the model’s output. A higher temperature means more randomness, while a lower temperature means less randomness.
- Top-p: This setting controls the diversity of the model’s output. A higher top-p means more diversity, while a lower top-p means less diversity.
OpenAI recommends to alter one, not both of these settings at a time. For example, if you want to increase the randomness of the model’s output, you should increase only the temperature.
- Frequency penalty and Presence penalty: This setting controls the repetition of the model’s output. A higher frequency penalty means less repetition, while a lower frequency penalty means more repetition.
During this blog post, we’ll be using the “chat” mode and “gpt-3.5-turbo” model. However, feel free to experiment with the other models and settings to see what works best for you!
The Prompt
The prompt is basically a text snippet that we feed into the LLM to get it to do something for us. It’s like a command that tells the model what we want it to do. For example, we can use a prompt to get the model to write code, answer questions, or solve math problems.
In example below (Figure 3), we’re using a prompt to solve simple math equation 2 + 2 = ?. The model gives us the correct answer 4 in the response and also shows us the steps it took to get there.
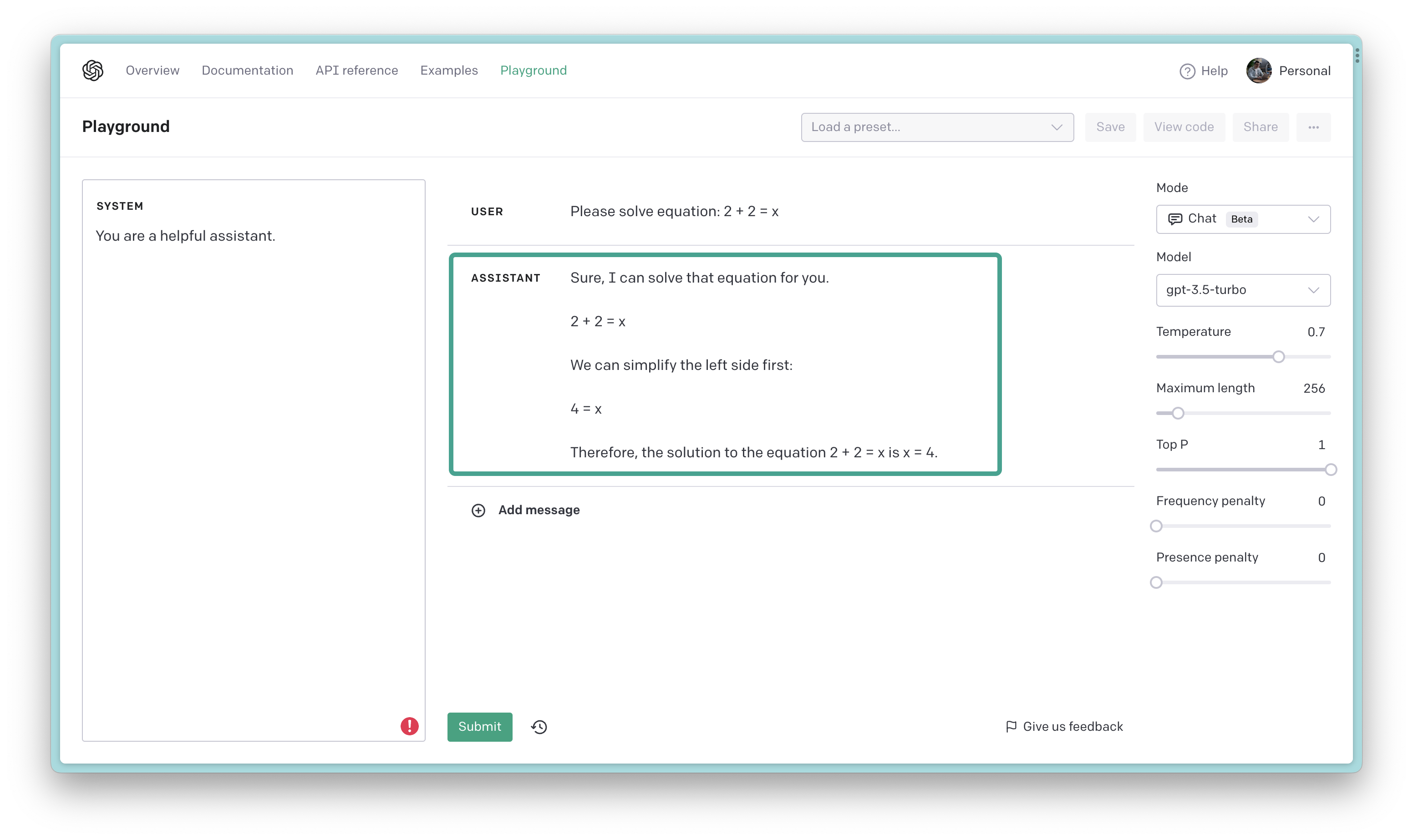 Figure 3: Using a prompt to solve a math problem
Figure 3: Using a prompt to solve a math problem
In general, the answer is correct, but… it’s not exactly what we were looking for. The model also generated a bunch of other stuff that we don’t need, like the steps it took to solve the problem and the answer to a different problem. This is where prompt engineering comes in handy!
However, we can design the prompt so that the model returns the specific answer we expect. For example, we can ask the model to return only the answer and nothing more:
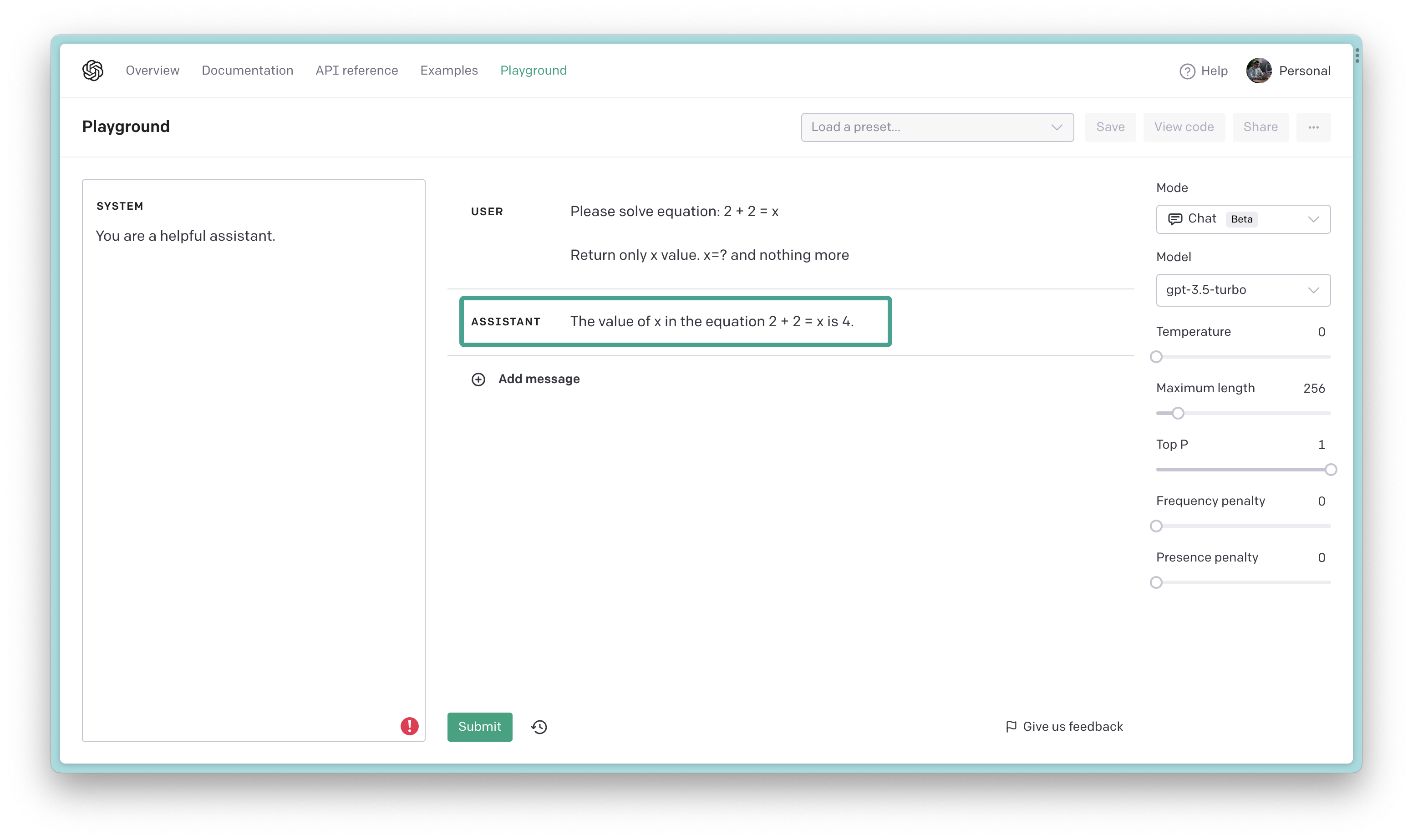 Figure 4: Using a prompt to solve a math problem with extra instructions
Figure 4: Using a prompt to solve a math problem with extra instructions
Unfortunately, the model still gives us extra stuff that we don’t need. It’s not exactly what we were looking for, but it’s a step in the right direction. We can use this as a starting point and keep tweaking the prompt until we get the desired result.
The Prompt Engineering Process
While interacting with LLMs we use prompts to get them to do what we want. However, the prompts we use are not always perfect. Sometimes they give us too much information, and other times they give us too little. This is where prompt engineering comes in handy!
When crafting prompts, it’s important to consider the various elements that make up an effective prompt. These elements work together to guide the LLM towards generating the desired output.
Let’s take a closer look at the typical elements of a well-designed prompt:
Instructions: Instructions are the guidelines or directives that help the LLM understand what you want it to do. Be clear and specific with your instructions to help the model grasp your intent. For example, if you’re looking for a summary, you might start with “Summarize the following article.”
Context: Context is the background information or details that help the LLM understand the scenario or topic. Providing relevant context can improve the quality and relevance of the model’s response.
Examples: Examples are the sample inputs and outputs that help the LLM understand the desired input and output. Providing relevant examples can improve the quality and relevance of the model’s response.
Input: The input is the actual data or information you want the LLM to process. This can include text, questions, or statements that the model will use to generate its response. Be mindful of the input you provide, as it directly influences the output you receive. If you’re looking for a summary of an article, for example, the input would be the text of the article itself.
Output: The output is the response or result that the LLM generates based on the input you provide. It can be anything from a short answer to a long-form article. The output is what you’re looking for, so make sure it’s relevant and useful to you.
Please note, that not all prompts will have all of these elements. Some prompts may only have one or two elements, while others may have all of them. It all depends on the task at hand and what you’re trying to accomplish.
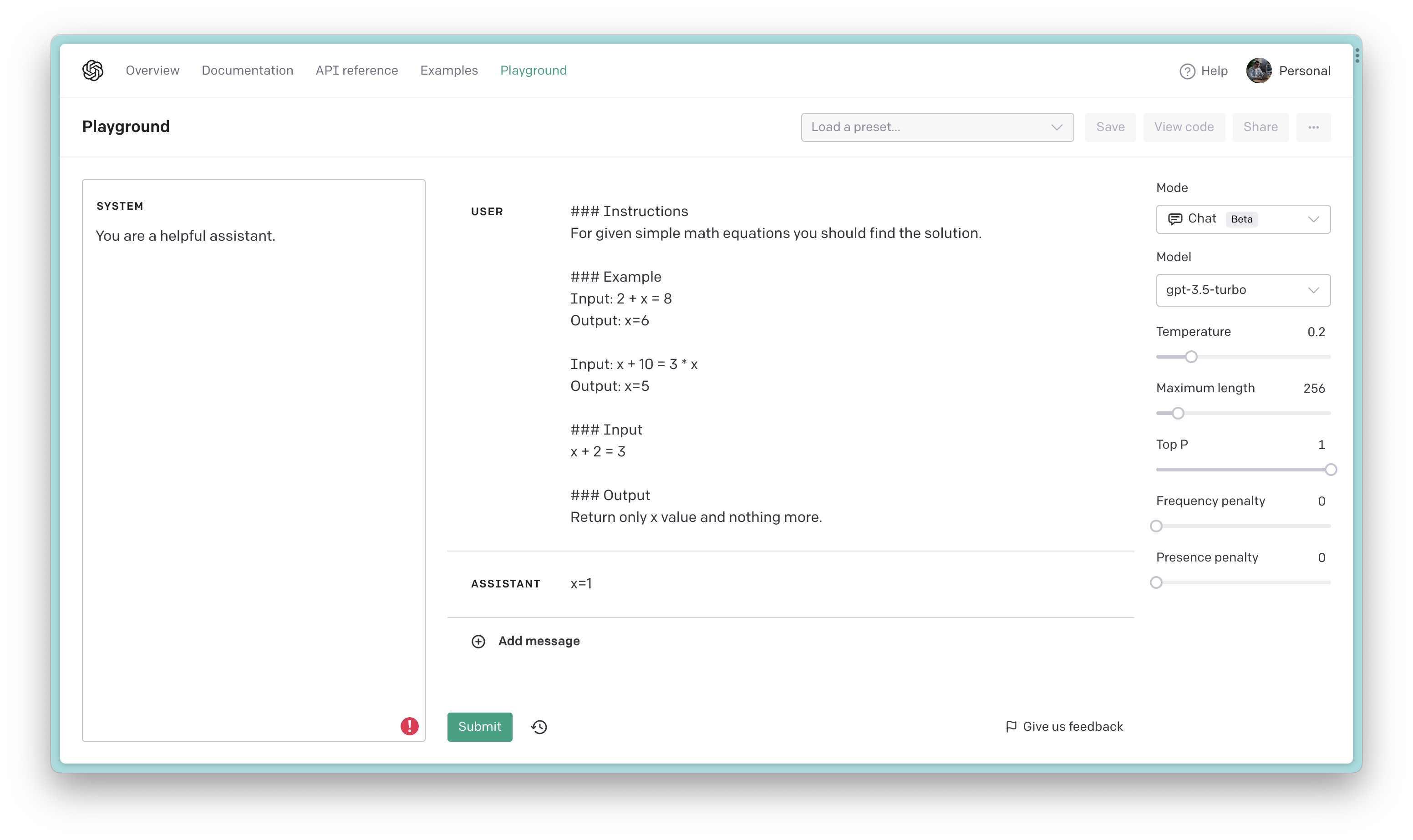 Figure 5: The elements of a well-designed prompt
Figure 5: The elements of a well-designed prompt
You’re probably wondering why I’m using ### in the example above (Figure 5). Well, it’s one of the many tricks I use to get the model to do what I want. In this case, I’m using it to tell the model for example that the text that follows is the input I want it to process. It’s a simple trick, but it works wonders! For more tricks, check out the OpenAI Guide.
Moreover, here are some best practices and tips to help you craft effective prompts that get the most out of your interactions with LLMs:
Be clear and specific: LLMs are more likely to generate useful output if your prompt is clear and specific. Instead of using vague or open-ended questions, try to focus on the details and make your intent obvious.
❌ Bad: Summarize the following article. ✅ Good: Summarize the given article in exactly 2 sentences. Make sure the summary is intended for a general audience.Provide context: Sometimes, LLMs need a bit of context to give you the best possible answer. If your question or statement requires background information, consider including it in your prompt.
❌ Bad: What is the biggest city in my state? ✅ Good: What is the biggest city in my state? My state is California.Allow, not deny: LLMs are more likely to generate useful output if your prompt allows them to do so. Instead of telling the model what not to do, try telling it what to do.
❌ Bad: Do not include the word "the" in your response. ✅ Good: Write a response that does not include the word "the".Describe the output: LLMs are very talkative, so it’s important to tell them what you want them to say. Instead of asking a question or making a statement, try describing the output you want to receive.
❌ Bad: What is the capital of California? ✅ Good: What is the capital of California? Write the answer in exactly 1 sentence.Give examples: Sometimes, LLMs need a bit of help to understand what you want them to do. If your prompt requires specific input or output, consider providing examples to help the model grasp your intent.
❌ Bad: What is the capital of California? ✅ Good: What is the capital of California? Example 1: The capital of Virginia is Richmond. Example 2: The capital of Florida is Tallahassee.Iterate and refine: Prompt engineering is an iterative process. If you’re not getting the output you desire, don’t be afraid to revise your prompt or adjust the LLM settings. Sometimes, a small tweak can make a world of difference in the quality of the generated response.
By keeping these best practices in mind and staying open to experimentation, you’ll be well on your way to mastering prompt engineering and making the most out of your LLM interactions.
For more amazing examples of correct and incorrect prompts, check out the Examples of Prompts section and explore OpenAI’s examples. Happy prompting!
GPT Limitations
As impressive and powerful as LLMs like GPT can be, it’s important to remember that they have their limitations.
One of the most notable constraints when working with these models is the token limit. Tokens are the individual units of text that the model processes, and there’s a maximum number of tokens that an LLM can handle in a single prompt and response.
Here’s a quick overview of how token limitations can impact your interactions with GPT:
- Input and output token limits: The total number of tokens in both the input prompt and the generated output must be within the model’s token limit. For instance, GPT-3 has a maximum token limit of 4096 tokens.
- Truncated or incomplete responses: If your prompt and desired response approach the model’s token limit, you might receive a truncated or incomplete output. The LLM may cut off its response to fit within the token constraints.
- Long prompts and reduced context: If you provide a lengthy prompt, the LLM may not have enough room to generate a comprehensive response. In some cases, the model may lose track of important context or details from the beginning of the prompt, leading to less accurate or relevant output.
To avoid these issues, it’s important to keep your prompts short and concise. If you need to provide additional context or examples, consider using a separate prompt for each one. This will help you stay within the model’s token limit and ensure that you receive the best possible output.
However, please note that in the future this limitations will be probably changed. For example, OpenAI has already announced that the GPT-4 will have a token limit of 8192 tokens.
Guiding the AI to Your Desired Outcome
As you’ve probably noticed by now, LLMs like GPT are very talkative. They can generate a lot of text in a short amount of time, which can be both a blessing and a curse. On the one hand, it’s great to have a model that can generate text quickly and accurately. On the other hand, it can be difficult to get the model to say exactly what you want it to say.
Well-designed instructions serve as a clear roadmap for the model, ensuring it understands your intent and stays on track while generating its response.
In the examples below, we’ll use the system message to guide the model to our desired outcome and to provide additional context for the prompt. We’ll also use the ### trick to split the prompt into separated parts. In the user message, we’ll provide the input we want the model to process.
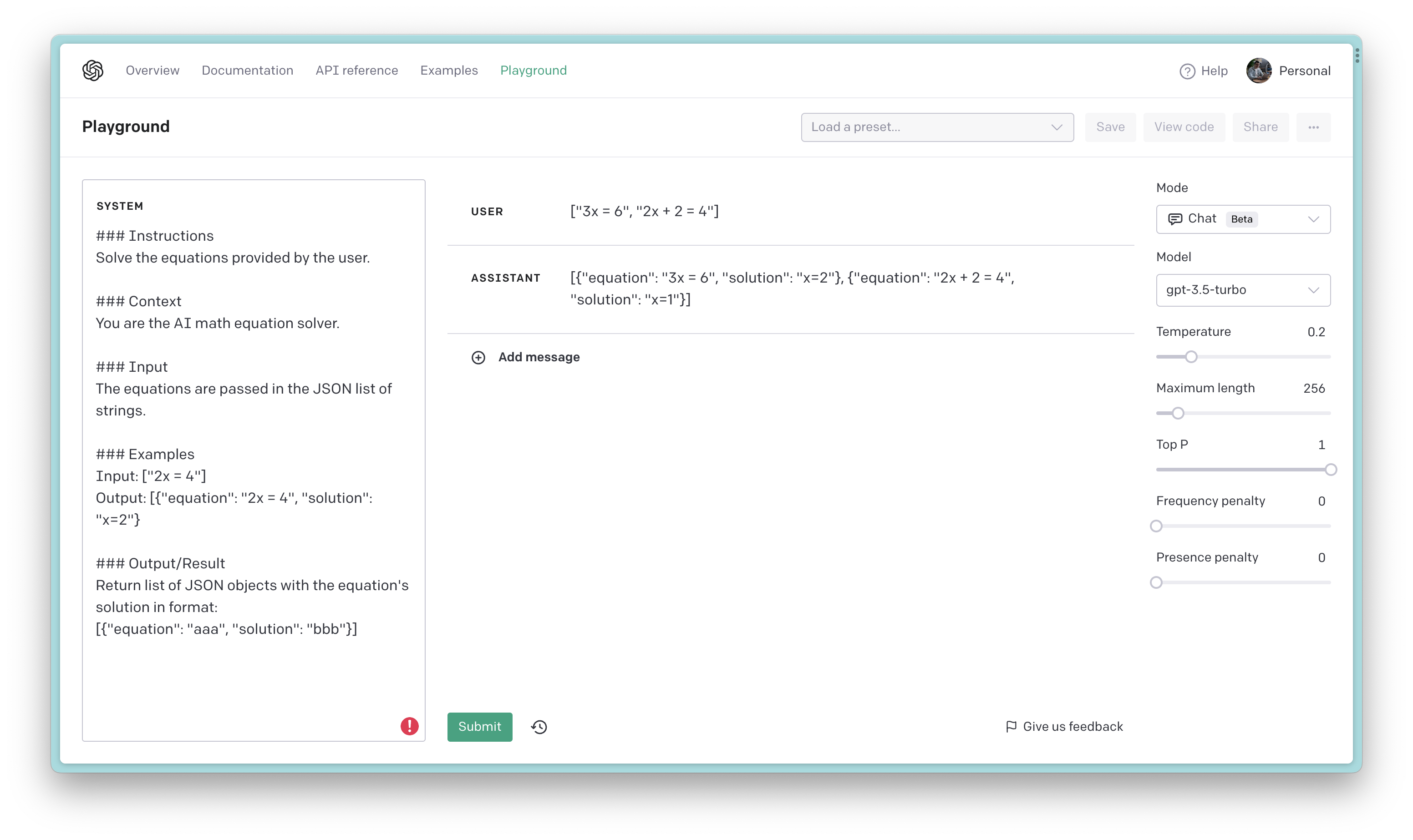 Figure 6: Guiding the model to solve a math problem
Figure 6: Guiding the model to solve a math problem
The example above (Figure 6) shows how we can use the system message to guide the model to solve a math problem. We start by telling the model what we want it to do, then we provide the input we want it to process. Finally, we tell the model what we want it to output.
By using ### to separate the prompt into instructions, context, input, examples and output, we can guide the model to our desired outcome and ensure that it stays on track while generating its response.
It’s worth noting the impressive ability of the GPT model to effectively process both JSON input and output. This feature can prove highly valuable when integrating the model with various applications.
Naturally, it’s important to remember that the operation of LLMs is primarily driven by probability and not always deterministic. This means that while we may provide clear instructions and context, the model might still occasionally generate outputs that don’t fully align with our expectations. However, with a carefully crafted prompt and a solid understanding of LLM behavior, we can significantly increase the likelihood of receiving accurate and relevant responses.
In our journey with prompt engineering, we have discovered that, by refining our techniques and understanding the nuances of LLMs, we can often guide the model to generate the desired output.
This involves a combination of providing explicit instructions, setting the right context, and iterating on our prompts as needed. As we continue to learn and experiment with different approaches, we’re able to harness the power of LLMs more effectively and achieve increasingly reliable results.
Prompting Techniques
Prompt engineering is an essential skill for working with LLMs, as it allows you to guide the model towards generating the desired output. Mastering various prompting techniques can significantly enhance your ability to harness the full potential of AI models like GPT.
Prompting techniques range from simple strategies, like providing clear instructions, to more advanced approaches, such as using templates or experimenting with model temperature settings.
There are many ways to prompt an LLM, and each technique has its own advantages and disadvantages. Most popular techniques are:
- Zero-shot learning
- Few-shot learning
- Fine-tuning
- Chain-of-thought
- Self-Consistency
and many more… While I won’t delve into the specifics of each technique in this blog post, I’d like to introduce you to the concept and encourage you to explore for a deeper understanding. You can find more information about these techniques in the Prompt Engineering Guide.
It’s worth noting that I’ve already incorporated some of these techniques in the examples provided throughout this blog post.
The Journey Continues
As we reach the end of this blog post, it’s important to remember that our exploration of prompt engineering and LLMs is far from over. The world of AI and natural language processing is constantly evolving, and there’s always more to learn, discover, and experiment with.
I hope this blog post has sparked your interest in prompt engineering and provided you with a solid foundation to build upon. As you continue on this journey, I encourage you to dive deeper into the topic, explore, and learn from the experiences of others in the AI community.
Remember, prompt engineering is both an art and a science, and it requires practice, patience, and persistence. Don’t be afraid to make mistakes or iterate on your prompting strategies.
In conclusion, the adventure of prompt engineering offers a fascinating and rewarding path towards harnessing the full potential of large language models. As you continue to expand your knowledge and refine your skills, you’ll unlock new possibilities and opportunities for meaningful AI-powered interactions.
The journey continues, and I’m excited to have you along for the ride. Happy prompting!